How It Works
From schema to synthetic rows in under 5 minutes.
Twynvex takes your data schema — or a real sample — and generates distribution-faithful synthetic rows with configurable tail coverage. No data sharing, no manual annotation.
Pipeline
Four steps. One clean synthetic dataset.
Each step in the pipeline has a direct SDK call or REST endpoint. Nothing black-box.
Schema Ingestion
Connect your schema or sample dataset
Upload a CSV or Parquet sample (Twynvex auto-detects column types, cardinality, and distributions) or define your schema directly in JSON. No data leaves your environment — Twynvex fits a statistical model from the sample and discards the raw records.
import twynvex as twx
# Option A: infer from sample
schema = twx.from_csv("transactions.csv")
# Auto-detected: 12 cols, 3 numeric, 4 categorical, 1 datetime
# Option B: define schema manually
schema = twx.Schema()
schema.add_column("amount", type="float", min=0.01, max=50000)
schema.add_column("label", type="categorical", values=["legit", "fraud"])Statistical Modeling
Twynvex fits marginal distributions and pairwise correlations
The engine fits each column's marginal distribution and a pairwise correlation matrix. For categorical columns, co-occurrence frequencies are captured. For numeric columns, the best-fit distribution family is selected (Gaussian, log-normal, power-law, uniform). This model is what generates synthetic rows — not the raw data.
# After from_csv(), the model is already fit.
# You can inspect it:
print(schema.summary())
# Column: amount | dist: log-normal | corr(label): 0.41
# Column: label | dist: categorical | P(fraud)=0.008
# Override any inferred parameter:
schema.columns["amount"].dist_params["mu"] = 4.2Generation with Constraints
Specify volume, tail weighting, class targets, and integrity rules
Configure the generation job: how many rows, how much to shift weight toward the distribution tail, target class ratios for labeled columns, and any hard constraints (referential integrity, numeric bounds, forbidden combinations). The constraint solver runs on every generated row before it enters the output buffer.
job = schema.generate(
num_rows=500_000,
tail_weight=0.4, # 40% of rows from distribution tail
label_ratio={
"fraud": 0.15 # 15% positive class
},
constraints=[
twx.Constraint("amount", ">", 0),
twx.Constraint("label", "fraud", requires={"amount__gt": 500})
]
)Output Delivery
Pull as DataFrame, push to S3, or stream from REST API
Synthetic output matches your source schema exactly — same column names, same types, same ordering. Download as CSV, Parquet, or JSON Lines. Push directly to S3. Or poll the REST API for the output URL once the job completes. Each job includes a fidelity report (JS divergence score), utility score, and privacy score.
# Poll until complete, then pull as pandas DataFrame
df = job.to_dataframe()
# 500,000 rows x 12 cols — schema-matched
# Or download directly
job.to_parquet("train_augmented.parquet")
# Or push to S3
job.to_s3("s3://my-bucket/synthetic/train.parquet")
# Quality report
print(job.report.fidelity_score) # 0.94
print(job.report.utility_auc) # 0.91
print(job.report.privacy_nn_dist) # 0.82 (higher = more private)Architecture
The privacy boundary is structural, not procedural.
Real records are used only to fit a statistical model. The model parameters — not the rows — are what the generation engine reads.
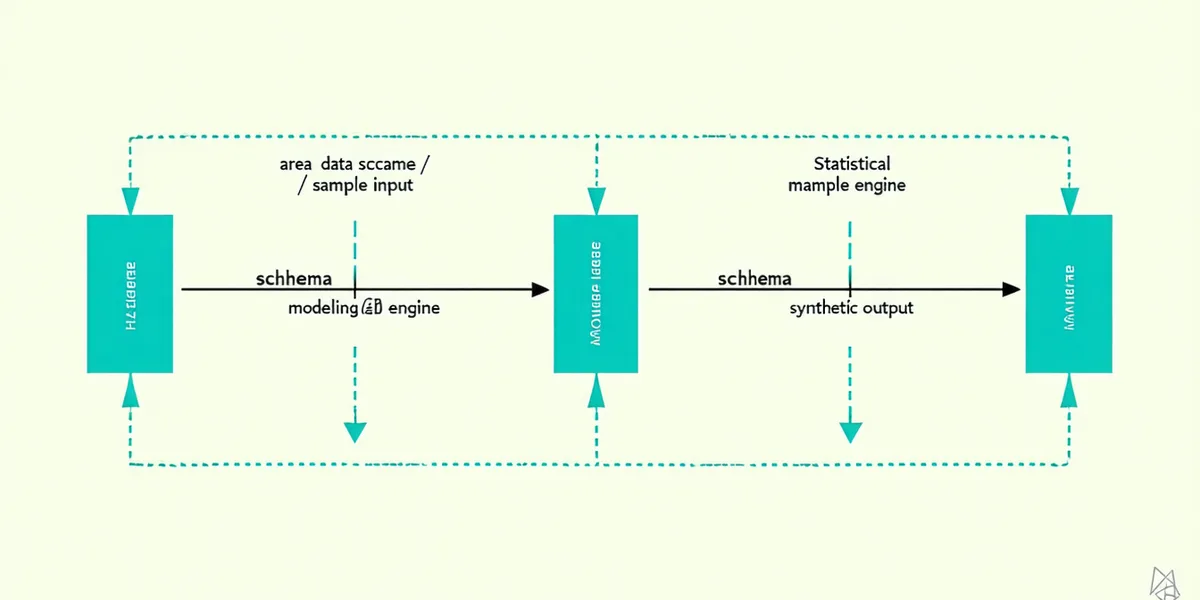
Quality Validation
How Twynvex validates synthetic quality.
Every generation job produces three scores. Each measures a different dimension of whether the synthetic data is actually usable.
Fidelity Score
Column-wise Jensen–Shannon divergence between real sample distribution and synthetic output distribution. Scores above 0.90 indicate the synthetic data mirrors the real data's statistical shape. Reported per-column and as an aggregate.
Utility Score
Train-on-synthetic, test-on-real (TSTR) evaluation. A classifier is trained on the synthetic output and evaluated on a held-out real sample. The resulting AUC is compared to a real-trained baseline. A score above 0.85 indicates the synthetic data preserves enough discriminative structure to be useful for downstream model training — not just statistically similar, but learning-useful.
Privacy Score
Nearest-neighbor distance check: for every synthetic row, we compute the minimum Euclidean distance to any real row in the sample. A score above 0.75 indicates no synthetic row is close enough to a real row to be considered a memorized copy. This is a structural check, not a compliance claim.